2021. 10. 5. 15:36ㆍ기타
이것보다 잘 쓸 자신이 없다.
출처 : https://redisle.tistory.com/14
혹시 글 사라졌을 경우에...
문자열 인코딩!
어느날 친구가 물어봅니다. "OO아~ 문자열 인코딩이 뭐야?"
갑자기 머릿속이 하얗게 변합니다. 문자열 인코딩... 분명 들어본적은 있는데 말이죠. 기억을 마구 더듬어봅니다.
예전에 인코딩을 찾아본적이 있었지, 한글이 제대로 안나와서 찾아봤었는데, 기억의 조각들이 한두개씩 발견됩니다.
EUC-KR, MS949, 유니코드, UTF-8 등등... 한번은 들어봤을법한 단어들이 머리속을 스쳐지나갑니다.
그런데 문자열 인코딩은 유니코드인가? UTF-8인가? 헷갈리기 시작합니다. 결국....
"문자열 인코딩, 그거..... 컴퓨터에서 한글 출력할때 쓰는거 잖아,
그 뭐냐, 그 UTF-8! UTF-8 그거 쓰면돼, 여튼 막 대충하면 돼....ㅎ"

문자열 인코딩이 뭐냐면, 어...음... 그니까, 그게....음........
분명 모르는건 아닌데 설명이 안됩니다... 누군가 물어봤을때 대충 얼버무리듯이 얼렁뚱땅 넘어간적 있지 않으셨나요?
(사실 제 이야깁니다)
주변 개발자들한테 (특히 주니어) 문자열 인코딩에 대해 물어보면 나오는 반응은 대개 아래와 같습니다.
문자열 인코딩에 대해 물어보면 나오는 다양한 반응들
프로그램을 만들다 보면 필연적으로 문자를 표시해야하는 상황을 자주 마주하게 됩니다.
어디서 들어는 봤지만 사실은 전혀 이해하지 못했던 "유니코드", "멀티바이트", "EUC-KR", "CP949", "문자열은 UTF-8이 국룰" 같은 문구가 생각나지 않으신가요?
왜 많은 사람들이 문자열 인코딩을 헷갈려할까요?
이유는 정말 간단합니다. 왜냐하면 문자열 인코딩이 정말 헷갈리기 때문입니다. ㅎㅎㅎ
알아야 할 개념들은 너무 많은데 단편적인 개념들이 조각조각 흩어져있어 이를 총망라하는 글이 없었으니까요!
하지만 너무 걱정하지마세요! 개념만 확실히 잡는다면 이해는 자연스럽게 하게 되실겁니다!
앞으로 이글을 통해 핵심과 원리를 아주 차근차근 설명해드릴테니까요!
많은 주니어 개발자들이 느끼는 문자열 인코딩
그런데 우리가 굳이 이걸 알아야 할까요?
물론 개략적으로 문자열 인코딩에 대해 알고 있다고 하더라도 컴퓨터가 문자열을 어떻게 처리하는지와 인코딩/디코딩 개념을 모호하게 잡고 간다면 개발중 어느 순간에는 반드시 헤매게 됩니다.
사실 문자열 인코딩 개념을 정확히 몰라도 개발하는데 큰 지장이 있지는 않습니다.
아래와 같은 난감한 상황을 마주치기 전까지는요.
개발자가 문자열 인코딩을 모른다면 생길 수 있는일





개념을 이해하지 못하고 사용하면 문제가 생겼을때 돌파할 수 없습니다.
그러니 앞으로 만나게 될 수도 있는 문제를 해결하기 위해 이번 시간에 공부해보자구요!

설명을 시작해볼까?
컴퓨터에서 문자를 표현해야 하는 이유?
컴퓨터는 구조적인 한계 때문에 모든 정보를 숫자로 밖에 표현할 수 없습니다.
컴퓨터가 발명되고 초창기에는 오로지 숫자를 통해서만 사람에게 정보를 전달했을겁니다.
50000,10000,5 같은 방법으로 말이죠. 이 숫자가 무슨 의미인지 파악이 되시나요?
50000,10000,5 라는 정보를 전달받은 사람은 다분히 당황했을겁니다.
저 숫자가 뭘 의미하는지 정확히 파악이 되지 않으니까요!
50000,10000,5 라는 숫자가 의미있는 정보임은 자명하지만 맥락을 파악할 수 있는 메타정보가 누락되어 있었기 때문에 정보 전달이 무척이나 어렵게 되버리고 말았습니다.
오로지 저 수치가 어떤 의미인지 메타정보를 알고 있는 사람들만 완전한 의미를 해석할 수 있을껍니다.
때문에 컴퓨터 공학자들은 고민에 빠지게 됩니다.
맥락을 담을 수 없는 숫자만으로는 사람에게 온전한 정보를 전달하기에 효율적이지 않았으니까요.
만약 "50000원을 10000원씩 나눠주면 5명에게 나눠줄 수 있습니다." 라고 컴퓨터가 메타정보까지 함께 실어 표현할 수 있다면 온전한 의미의 정보를 전달할 수 있을겁니다.
필연적으로 숫자밖에 다룰 수 없는 컴퓨터에서 숫자 말고도 문자를 표현할 수 없을까? 하는 고민을 하게 되었지요.
다행히도 전세계 모든 언어에는 공통점이 있습니다. 세상의 모든 언어들은 "기호(문자)"로 이루어져 있으며 기호는 0부터 무한대까지 표현가능한 수와는 달리 경우의 수가 무한하지 않고 한정되어 있습니다.
이 특성으로 인해 전세계의 모든 문자는 유한한 범위로 제한된 문자 집합(Character Set)으로 표현할 수 있습니다.
숫자밖에 다룰 수 없는 컴퓨터를 위해 우리는 숫자와 문자간의 대응관계를 나열해 놓은 테이블(Table)이 필요로 합니다.
문자 집합을 숫자로 주욱주욱 나열해놓은 테이블말이죠.
이를 위해 "부호화(Encoding)" 과정이 필요하게 되었습니다.

매트릭스의 네오처럼 세상이 숫자로 보일 정도면 컴퓨터와 직접 대화해도 된다
인코딩/디코딩(부호화/복호화)이란?
인코딩(부호화)은 바로 이것입니다. 정보를 어떠한 목적을 가지고 또 다른 형태의 정보로 변환(Transform)시키는 행위를 의미합니다. 숫자밖에 다룰 수 없는 컴퓨터를 위해 인간이 이해하기 위한 도구인 "문자"를 "숫자"로 변환하는 이 과정도 인코딩의 범주에 속합니다.
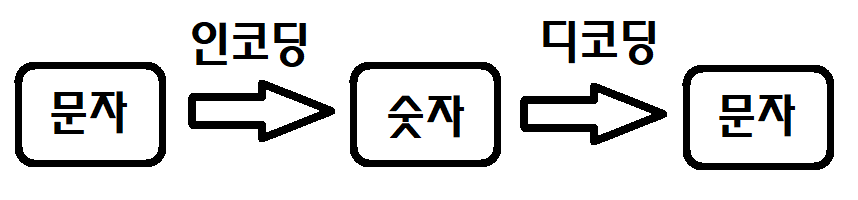
인코딩은 정보를 다른 정보로 변환하는것 디코딩은 다른 정보로 변환된 정보를 원래 정보로 다시 되돌리는것이다
"엥? 내가 예상했던 문자열 인코딩이랑은 개념이 다른데?" 라고 생각하셨을 수도 있을겁니다. 그렇다면 제대로 보셨습니다. 이것은 문자열 인코딩을 설명하는게 아닙니다. 일반적인 인코딩/디코딩의 개념을 설명하는겁니다.
컴퓨터를 위해 문자 여러개를 숫자로 인코딩하면 결과물로 문자와 숫자가 1:1로 대응되는 테이블이 나오게 됩니다.
이 테이블이 위에서도 여러번 언급했던 문자 집합(Character Set) 입니다.
문자 집합을 반복적으로 언급하는 이유는 문자 집합과 문자열 인코딩을 많은 사람들이 헷갈려 하기 때문입니다.
문자 집합과 문자열 인코딩은 다르다
아마 이 부분이 문자열 인코딩을 이해하는데 있어서 가장 헷갈리는 부분일겁니다.
문자 집합은 문자를 숫자로 매핑시켜놓은 테이블입니다! 문자를 숫자로 인코딩 한것은 맞지만 이게 문자열 인코딩은 아닙니다!
문자 집합과 문자열 인코딩, 이 둘은 비슷하지만 사실 약간 의도가 다른 인코딩입니다.
예시를 들어 설명하는것이 가장 쉽고 전달이 쉬울것 같기에 가정을 해보겠습니다.
머나먼 지구 어딘가엔 평화로운 햇님나라가 있었습니다.
햇님나라 사람들은 오로지 A,B,C,D 4글자만으로 의사소통을 합니다. 어느날 햇님나라 사람들은 컴퓨터를 사용하고 싶었고 그들의 문자를 컴퓨터가 이해할 수 있게 숫자로 변환(인코딩) 했습니다. A는 10, B는 20, C는 30, D는 40 으로 말이죠.
햇님나라 사람들은 이렇게 만든 테이블을 정리해놓고 "햇님 표준전산 문자집합"이라고 이름 붙혔습니다!
| 햇님 표준전산 문자집합 | |
| A | 10 |
| B | 20 |
| C | 30 |
| D | 40 |
햇님나라에서 사용되는 컴퓨터들은 이제 20을 B로, 40을 D로 인식할 수 있게 되었습니다.
ACDDB라는 문자를 표현하고 싶을때 1030404020 으로 컴퓨터에게 전달하면 컴퓨터는 이걸 디코딩하여 ACDDB로 표시 해주었습니다.
그렇게 한동안은 잘 사용하는듯 싶었습니다... 그런데 어느날 햇님 나라 프로그래머들은 글자를 표현하려면 항상 10, 20, 30, 40 두글자를 써서 글자를 표현해야 하는점이 몹시 불편했습니다. 프로그래머들은 이걸 어떻게 해결할 수 없을까 하는 고민에 빠지게 되었고 어떤 프로그래머가 숫자 뒤에 0을 빼버린 전산 문자 집합을 새롭게 정의하자고 제안합니다!
프로그래머들끼리 수근수근대는 가운데 한 프로그래머가 말합니다.
"지금까지 쭈욱 사용해왔던 '햇님 표준전산 문자집합'을 변경해버리면 지금까지 A 문자를 표현하는데는 10 하나 밖에 없었는데 옛날에 만들었던 프로그램들은 새롭게 바뀐 숫자 1을 문자 A라고 절대 인식 못할거에요! 분명 엄청나게 헷갈릴겁니다! 그래서 저는 반대에요"
하고 항변합니다. 음..... 일리가 있는 말이군요! 문자집합이 이중화 되면 바꾸는데 정말 많은 에로사항이 생길건 확실해보입니다.
그때 조용히 있던 프로그래머가 입을 뗍니다.
"사실 문제가 생기는 부분은 우리가 사용할때 불편해서 그런거잖아요? 그럼 우리끼리 정보를 주고 받을때, 정보를 저장할때만 저희가 한번 더 변환하면 어때요? 우리끼리는 편하게 주고 받다가 나중에 실제로 컴퓨터가 인식해야 할때만 다시 문자집합으로 변환 해주면 되지 않겠어요?"
모두들 조용히 고개를 끄떡입니다. 다들 수긍하는 분위기네요.
그렇게 햇님나라 프로그래머들은 모여서 "햇님 표준 인코딩 방식"을 제정합니다.
| 햇님 표준 인코딩 방식 | |
| 10 | 1 |
| 20 | 2 |
| 30 | 3 |
| 40 | 4 |
이제는 ACDDB 표현하기 위해서 13442로 표현하면 되었습니다. 프로그래머가 만든 프로그램들간에는 햇님 표준 인코딩 방식이 적극적으로 사용되었고 13442를 컴퓨터에 표시해야 하는 시점에 햇님 표준전산 문자집합인 1030404020으로 디코딩하였고 이를 다시 ACDDB로 디코딩 해주니 정상적으로 글자가 표시되었습니다.
여기까진 좋았습니다. 그런데 아뿔싸,,, 컴퓨터 로직에 문제가 생겨서 1~4까지의 숫자가 다른 용도로 사용되어야 하는 상황이 발생하고 말았습니다. 이 문제 때문에 특정 프로그램들은 정상적으로 문자 A,B,C,D가 출력되지 않는 버그가 생기고 말았습니다.
이에 햇님나라 프로그래머들은 문제점 해결을 위해 다시 뭉쳐서 머리를 모았습니다.
하지만 이번에는 처음과는 달랐습니다. 큰 고민없이 문제를 해결하기 위해서 간단하게 0을 빼고 5씩을 더한 "햇님 꼼수 인코딩 방식"을 정의하고 사용하기로 서로 약속했습니다.
| 햇님 꼼수 인코딩 방식 | |
| 10 | 6 |
| 20 | 7 |
| 30 | 8 |
| 40 | 9 |
ACDDB를 68997로 표현했고 위와 같은 원리로 문자집합으로 디코딩하여 1030404020을 다시 ACDDB로 표현할 수 있었습니다.
이렇게 햇님나라 프로그래머들은 "꼼수 인코딩 방식", "표준 인코딩 방식"을 상황에 따라 번갈아 가며 사용하여 문자열 깨짐 버그없이 프로그램을 짤 수 있었고 덕분에 야근하지 않고 6시에 칼퇴해서 오래오래 행복하게 잘 살았답니다....

아무래도 예시가 좀 구린거 같다...
예시를 만들기 위해서 다소(꽤많이) 과장했지만 문자집합과 문자열 인코딩이 어떤 차이점이 있는지 비유적으로 설명하기 위해 노력했습니다. (노력 많이 했는데 알아주시면 감사합니다.)
위 예시를 읽다보면 이런 의문이 들 수 있습니다.
"엇! 그러네! 문자열 인코딩을 왜 하죠? 사실 문자를 숫자로 변환하는 과정이 이미 인코딩 한건데 그걸 한번 더 인코딩 하는거 아닙니까?"
정말 날카로우시네요! 정확하게 맞습니다! 컴퓨터가 이해할때 필요한 문자 집합을 새로운 규칙을 통해 한번 더 인코딩 하는 과정이 바로 "문자열 인코딩" 입니다.
사실 우리는 문자 집합을 만드는 과정에서 이미 한번 인코딩을 했습니다. 위에서 언급했듯이 문자 집합을 만드는 과정 또한 컴퓨터에게 문자를 인식시키기 위한 인코딩이 맞기 때문입니다. 그렇기 때문에 문자집합과 인코딩이 동일한 경우도 있습니다! 대표적으로 바로 아래에서 설명할 누구라도 들었을 ASCII 인코딩이 그렇습니다. ^0^
하지만 문자열 인코딩을 구태여 한번 더 하는 이유는 이렇게 했을때 얻을 수 있는 좋은 장점이 있기 때문입니다~!
이 장점에 대해서는 뒤에서 자세히 설명하도록 하겠습니다.
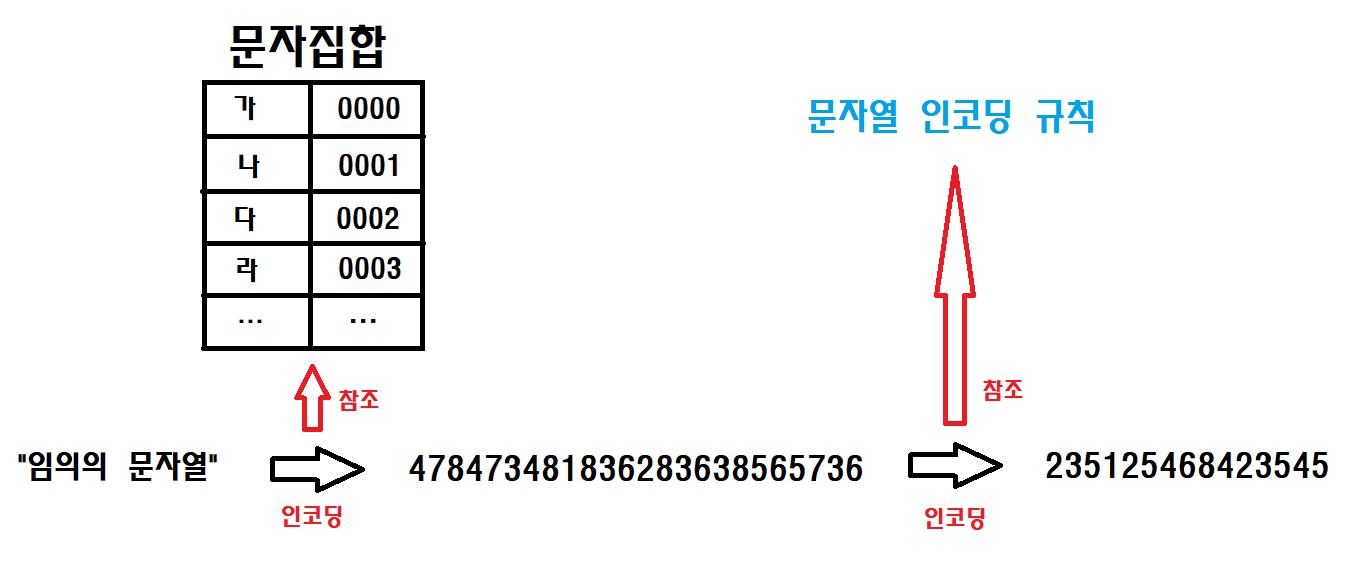
글이 길어 짧게 3줄 요약 해보겠습니다.
1. 문자 집합을 만드는 것도 인코딩이다.
2. 문자열 인코딩은 인코딩 된 문자 집합을 한번 더 인코딩 하는것이다.
3. 문자 집합과 문자열 인코딩이 같은 경우도 있다. (즉, 별도의 문자인코딩 없이 문자 집합을 그대로 쓰는 경우도 있다)
태초에 ASCII가 있었다
최초의 문자집합인 ASCII(American Standard Code for Information Interchange) 테이블은 가장 대표적인 문자집합이자 인코딩 입니다.
printf 를 타이핑하던 추억의 그때가 기억나십니까?
컴퓨터가 발명된 영미권에서 문자를 표현하기 위해 아주 초창기에 도입된 암모나이트급 문자집합입니다.
워낙 유명하고 모르는 사람이 거의 없을것이기 때문에 구구절절히 설명하진 않겠습니다.
문자집합과 인코딩이 똑같은 형태이고 7비트의 고정길이를 가지고 있습니다.
얘는 좋은데, 한글 표현이 안되요.. ㅜㅅㅜ
한글을 표현하기 위한 눈물나는 노력
ASCII 코드가 널리 사용되었지만 곧 컴퓨터가 세계적으로 보급되면서 영문자가 아닌 문자들을 표현하려는 노력 또한 세계 곳곳에서 이루어지기 시작했습니다. 세계 각국에서 자신들의 문자 체계를 표현할 수 있는 독자적인 문자 집합을 정의하게 되었고 세계는 문자전국시대에 접어들게 됩니다.
이 혼란스러운 와중에 한국에서도 한글 표현을 위한 문자집합 제정에 대한 논의가 오고 갔습니다.
한글을 표현을 위해 문자 하나당 몇 바이트를 할당할 것이며 문자집합에 어떤 문자를 담을것인가?를 말입니다.
오랜 논의 끝에 1987년 대한민국 국가기술표준원에서는 한글자당 2byte의 고정길이를 가지는 "한국 표준 문자집합" "KSC 5601-1987"을 제정하는데....
- 1행, 2행: 각종 기호
- 3행: 전각 ASCII 문자(백슬래시(\)를 원화 기호(₩)로, 물결표(~)를 오버라인( ̄)으로 바꿈)
- 4행: 한글 자모
- 5행: 로마 숫자, 그리스 문자
- 6행: 괘선 기호
- 7행: 단위 기호
- 8행: 확장 라틴 문자 대문자, 동그라미 안 한글·라틴 문자·숫자, 분수 기호
- 9행: 확장 라틴 문자 소문자, 괄호 안 한글·라틴 문자·숫자, 위 첨자와 아래 첨자
- 10행: 히라가나
- 11행: 가타카나
- 12행: 키릴 문자
- 16행 ~ 40행: 한글 2,350자 ??!
- 42행 ~ 93행: 한자 4,888자 (왜 한글보다 한자가 더 많냐...(⊙_⊙)?)

2,350자가 충분하다니... 미쳤습니까 휴먼?
무려 표준으로 정의된 문자집합이 표현할 수 있는 한글의 가짓수가 2,350자로 제한되어 표현에 심각한 제약이 생기는 차마 눈물 없이는 볼 수 없는 상황이 발생하고야 말았습니다. 이는 표현해야 할 전체 한글 가지수의 21% 밖에 되지 않는 수치입니다.
이로인한 재미난 이야기거리도 있는데 1991년도 까지는 우리가 지금 "펩시콜라"로 알고 있는 브랜드의 정식 명칭이 원래는 "펲시콜라" 였습니다.

1991년도 펲시콜라 광고이다. 당시 한글 표현으로는 '펲'을 표현할 수 없었다.
그런데 1992년부터 펩시콜라로 바뀌었다고 하는데 그 이유가 한글 표준 문자집합에 "펲" 자가 누락되어 있어 펲시를 펲시라 부르지 못했기 때문에 "펩시콜라"로 바뀌었다는 그런 (출처는 불분명한) 우스갯소리도 있습니다.
농담조의 루머겠지만 실제로 컴퓨터를 통해 한글을 표현할때 이따금씩 이런 표현의 불편함을 겪은 것은 사실입니다.
더불어 문자열 인코딩 방식에 있어서도 뜨거운 논쟁이 오고갑니다.
한국이 다른나라들 보다 더 어려웠던 것이 글자를 선상에 순서대로 주르륵 나열하면 되는 영어, 한자와는 달리 한글은 문자 특성상 자음과 모음을 조합하여 글자를 표현할 수 있었기 때문에 초성 + 중성 + 종성을 조합해서 한글을 표현하자는 조합형 한글 인코딩파와 모두 합쳐서 완성된 문자로 표현하자는 완성형 한글 인코딩파 두 갈래로 나뉘어 갈피를 잡지 못하고 있었기 때문입니다.
"사랑해"라는 한글 문자열을 인코딩할때
조합형 한글 인코딩파는 "ㅅ"+"ㅏ"+"ㄹ"+"ㅏ"+"ㅇ"+"ㅎ"+"ㅐ"로 표현하자는 것이었고
완성형 한글 인코딩파는 "사"+"랑"+"해" 로 표현하자는 것이었습니다.
이 둘은 첨예하게 대립하였으며 각자 자신이 주장하는 인코딩의 우수성과 반대편 인코딩의 단점을 열거하며 디스전을 펼쳐갔습니다.
조합형 한글 인코딩파
조합형의 장점

1. 조합형을 사용하면 자음과 모음의 모든 조합을 표현할 수 있기 때문에 표현 가능한 한글 가지수는 160만개가 넘는다. (아니 근데, 한글 조합이 그렇게 많았어? 한국인들 단체로 동공지진 (⊙_⊙;;))
2. 조합형을 쓰면 사라졌던 옛한글도 표현할 수 있지롱~
완성형의 단점
1. 너넨 옛한글 표현 못하잖아? ㅎㅎ 나랏〮말〯ᄊᆞ미〮 해봐!! 나랏〮말〯ᄊᆞ미〮!!
2. 완성형 너넨 미리 조합되어 있는 문자가 아니면 나타낼 수 있는 방법 자체가 없잖아? 그에 비해서 우리는 조합해서 나타낼 수 있다고. (물론 "나타낼 수" 있다고 했지 보여줄 수 있다곤 안했다. ㅎㅎ)
완성형 한글 인코딩파
완성형의 장점
1. 우린 초중종성을 해석하는데 들어가는 부하를 줄일 수 있다. 한글 한글자를 표현할때마다 최소 2개(초+중)에서 최대 5개(초+중1+중2+종1+종2) (ex) 뷁)) 의 한글 문자를 해독해야 되는데 완성형을 쓰면 한글자씩 해독 없이 편하걸랑~ ^^ 부럽니? 부러우면 부럽다고해~ ^^
조합형의 단점
1. 160만가지의 한글은 "이론상"이나 가능한거고 실제로 한글 조합으로 표현할 수 있는 가짓수는 1만개가 조금 넘는 수준이다. 만들 수도, 쓸 수도 없는 문자 조합해서 뭐하냐? ㅎㅎ
2. 아니~ 시대가 어느 시댄데 옛한글을 요즘 누가 쓰냐 ㅡㅡ "라떼는 말이야~ 나랏〮말〯ᄊᆞ미〮듕귁〮에〮달아〮문ᄍᆞᆼ〮와〮로〮 서르 ᄉᆞᄆᆞᆺ디〮 아니〮 했어~ 요즘 것들은~~ㅉㅉ" 라도 쓰고 싶은거냐? 너무 오버하는거 아니냐~ 그리고 못하는게 아니라 안하는거야! 비효율적이어서 안하는거라고!
3. 자모 하나하나 조합해서 언제 한글자 만들래? 너 CPU가 차~암 좋은가보다?? 어휴 비효율~!!
4. 그리고 조합형 안에서도 인코딩이 여러개인데 용량도 각자 다르고 대충 봐도 엄청 복잡한데 정말 표준 맞출 수 있겠어?
결국 이 과정속에서 완성형파는 "청계천 한글"이나 그 유명한 "EUC-KR", "CP949(MS949)" 같은 완성형 한글 인코딩 방식을 사용하게 되었고 조합형파도 나름대로 "3바이트 조합형", "2바이트 조합형", "N바이트 조합형" 같은 조합형 인코딩 방식을 사용하면서 한글 표현 대혼란기가 도래하고 말았습니다.
서로 다른 인코딩을 쓰는 프로그램간에는 당연하게도 정상적으로 한글을 표현할 수 없는 호환성 문제가 발생했고 이는 한글 표현이 어려워지고 프로그램의 잔버그가 많아지게 되는 원인을 제공했습니다.

혼란의 한글 인코딩
하지만 문제는 지금부터 시작이었습니다. 인코딩을 통일시키고 제한된 한글 문자집합 내의 엄선한 단어들만 표현한다고 하더라도 피할 수 없는 치명적인 문제였습니다. 문제는 한글 표시를 위해 "한글 표준 문자집합"을 사용하여 개발된 프로그램은 해당 문자집합 내에서 표현 가능한 한글, 영어, 한자 일부, 일본어 일부의 제한된 글자만 표현할 수 있다는 점입니다. 아무리 한글이 과학적이고 자랑하고 싶은 언어라고 하더라도 다른 나라 사람들은 이해할 수 없는 문자입니다. 때문에 외국인들을 위해 다른 나라의 문자 또한 표현해야 합니다. 프로그램은 점점 글로벌화 되어 지역을 벗어나 외국의 문자들까지 포괄해야 하는 상황에 놓이게 되었습니다.
한글, 영어, 일본어, 중국어 말고도 그리스, 터키, 프랑스, 독일, 베트남, 인도 등등... 타 국가의 문자들까지 지원하는 프로그램을 만들기 위해선 어떻게 해야할까요?
이를 위해서는 프로그램에서 표출되는 모~~든 문자열들을 각 국가별 표준 문자집합과 인코딩에 맞게 변환하여 관리해야 합니다. 이는 엄청나게 번거로울 뿐더러 굉장히 버그 발생 가능성이 높은 하기 짜증 나는 일입니다.
이렇게 엄청난 노력을 들여서 국가별 표준 문자집합과 메인스트림 인코딩을 사용한다고 하더라도 근본적인 문제는 해결할 수 없습니다. 특정 A라는 문자집합을 통해 표현된 문자열은 다른 B라는 문자집합과 호환되지 않습니다.
예를들면, 한글 표준 문자집합에는 인도 문자는 존재하지 않으므로 한글과 인도 문자를 동시에 표시하는것은 절대 불가능한 일이 되어버렸습니다. 즉, 문자 집합의 한계가 표현의 한계였습니다.
(비단 한국만의 이야기는 아니었습니다. 이러한 문자집합의 지역성은 프로그램의 세계화를 발목 잡는 큰 걸림돌이었습니다.)

문자집합의 지역성은 프로그램의 세계화를 방해했다
머리 좋은 컴퓨터 공학자들이 이 파국으로 치닫는 상황을 좌시할리 없습니다.
이를 극복하기 위한 대안을 내놓습니다.
이 혼돈의 카오스를 끝내러 왔다, 유니코드의 등장
유니코드의 탄생 배경을 알기 위해 먼길 오셨습니다. 유니코드는 갈수록 세계화, 일반화 되어가는 프로그램 내에서 문자의 일관성 있는 처리를 위해 고안된 모든 국가에서 사용되는 문자들을 포함하는 문자집합입니다.
문자집합이 세상에 존재하는 모든 문자 체계를 포괄할 수 있다면 문자열 안에서 한글, 힌디어, 한자, 히라가나, 베트남어 등을 모두를 표현할 수 있을것입니다.
유니코드는 전세계 모든 문자를 표현하는 문자집합이다
"엥?! 잠시만요! 전세계의 모든 문자들을 표현한다구요? 그게 가능한가요? 문자들이 엄청 많을것 같은데요?"
물론 국가별로 사용하는 문자들이 많지만 예상과는 다르게 문자의 개수가 천문학적으로(말도 안되게) 많지는 않습니다. 그 이유는 세계에서 사용되는 대부분의 문자들이 소리를 표현한 표음문자(소리글자)이기 때문입니다. 세계 대부분의 언어들은 그 체계가 달라도 소리를 기호화 한 자음과 모음을 조합한 형태로 단어를 표현하고 있습니다. 아무리 자음과 모음의 종류가 나라별로 다양하다고 하더라도 사람의 구강 구조상 발성 방법에는 한계가 있기 때문에 그 가짓수가 대개는 수십가지 정도에 그칩니다. 때문에 표음문자는 생각보다는 자모의 가짓수가 많지 않아 유니코드에 전세계의 대부분의 문자를 담는게 가능한 것입니다.
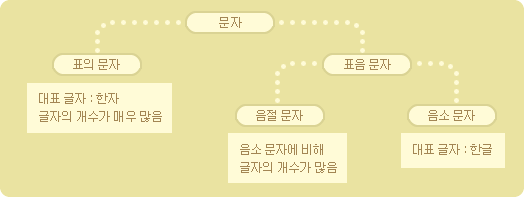
소리를 표기하는 표음문자는 글자를 표기하는데 큰 장점이 있다.
유니코드의 크기는 얼마나 될까?
우선 유니코드가 얼마나 많은 가짓수를 표현할 수 있는지 알아야겠군요? 유니코드는 글자 하나당 2~3byte의 크기를 가집니다. 가장 작은 2byte는 16비트이고 대략 65,500가지가 조금 넘는 문자를 표현할 수 있습니다.
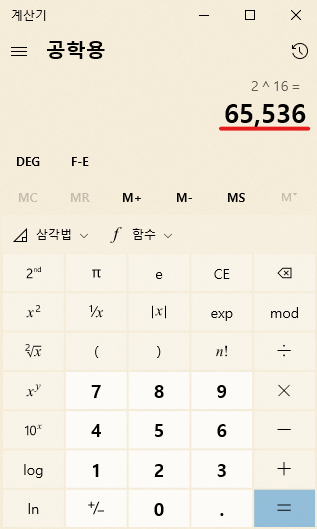
2바이트(16비트)로는 최대 65536 가지 경우의 수를 표현할 수 있다.
어라?! 2byte면 위에서 언급했던 "한국 표준 문자집합"과 같은 크기입니다. 겨우 한글을 2,350자 밖에 표현할 수 없었던 바로 그 문자집합이요! 같은 2byte인데 유니코드는 도대체 어떻게 이루어져 있길래 이게 가능한걸까요?
아무래도 유니코드의 구조에 대해서 조금 더 알아봐야 될것 같습니다.
유니코드의 구조
유니코드는 평면이라고 하는 세부 영역으로 나누어 관리되고 있습니다. 크게 기본평면(Basic Multilingual Plane)과 보조평면(Supplementary Multilingual Plane)으로 나눠져 있습니다.
기본평면, BMP(Basic Multilingual Plane)
유니코드에서 가장 자주 사용되고 핵심이라고 볼 수 있는 0~2바이트까지의 영역을 BMP 혹은 "다국어 기본 평면" 영역이라고 합니다. 거의 대부분의 문자들이 해당 영역에 정의되어 있습니다.
유니코드는 16진수로 표시할 수 있는데 앞에 유니코드임을 의미하는 U+기호와 16진수를 합쳐 표시합니다.
범위가 2byte 까지이므로 4개의 16진수로 표현가능한 범위 즉, U+0000 ~ U+FFFF 안에 속하는 유니코드 문자가 바로 다국어 기본 평면에 해당합니다. 아래 표를 보면 비어있는 공간이 거의 없이 빼곡하게 차있는 것을 확인할 수 있습니다.
이 영역에는 라틴 문자, 동아시아 문자, 중동 문자, 특수기호, 한자, 동남아시아 문자, 중앙아시아 문자, 아프리카 문자 등 다양한 문자들이 정의되어 있습니다.

유니코드 앞의 2자리 16진수(Most Significant Byte) 별로 나눈 BMP 테이블 카테고리
보조평면, SMP(Supplementary Multilingual Plane)
SMP는 3바이트의 영역을 가지는 "다국어 보조 평면" 영역입니다. U+10000 ~ U+1FFFF 의 영역을 가지며 2byte라는 공간 제약상 BMP에 모두 담을 수 없었던 문자들(한자, 중앙아시아 문자 등)을 추가적으로 표현하기 위해 사용되는 평면입니다. 또한 특수문자나 이모티콘(이모지), 기호들도 정의되어 있습니다.
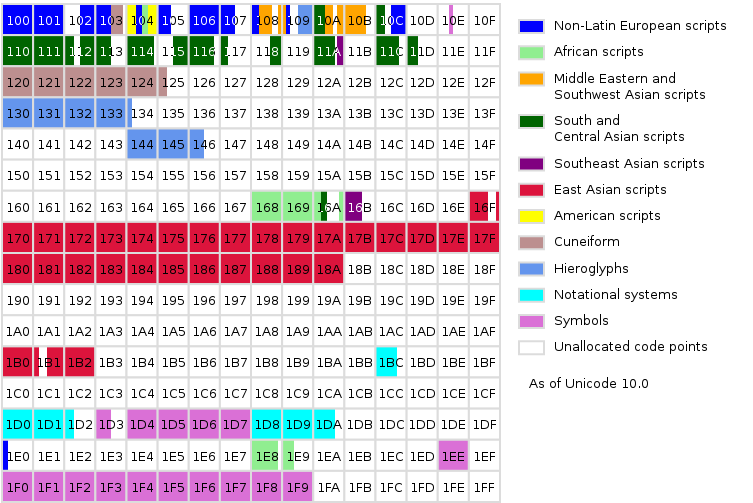
유니코드 앞의 3자리 16진수 별로 나눈 SMP 테이블 카테고리
SMB 영역에 정의되어 있는 특수문자와 기호들
이렇듯 유니코드는 크기가 2byte 고정이 아닌 2~3 byte로 가변적인 크기를 가지고 있습니다!
한개의 평면은 최대 2byte의 표시 범위를 가지며 유니코드는 3byte까지 표현 할 수 있으므로 BMP(U+000000~U+00FFFF)를 제외하고도 U+01~FF까지 총, 255개의 평면을 추가로 표현할 수 있습니다.
때문에 U+AABBBB로 표현되었을때 AA는 평면 인덱스, BBBB는 문자 인덱스 로 인식하면 됩니다.
아래 표를 통해 보조 다국어 평면(SMP:U+01) 말고도 보조 표의문자 평면(SIP:U+02), 표의문자 평면(TIP:U+03), 보조 특수 문자 평면(SSP:U+14), 사용자 자유 영역(PUA:U+15~16) 등을 확인할 수 있습니다.
3byte의 경우의 수는 16,777,216(1,677만) 가지나 되기 때문에 현재 대부분의 평면은 비어있습니다.

유니코드에서 한글의 비중은 어떻게 될까?
유니코드의 BMP 영역이 사실상 유니코드의 정수라는 것을 이해 하셨을겁니다. BMP 영역은 대부분의 문자들이 들어있는 영역이니까 해당 영역 안에 한글이 들어가 있을겁니다. 전세계 모든 문자를 포함하는 유니코드에서 한글은 어느 위치에서 어느정도 비중을 차지하고 있을까요?
비중이 높을까요? 낮을까요? 놀라지 마세요~! 한글은 BMP 영역의 무려 17%나 차지하고 있답니다!!!!
17%는 전체 표현가능한 65,536가지 중 11,184가지이며 이는 상당한 수치임을 대략적으로 봐도 인지할 수 있습니다.
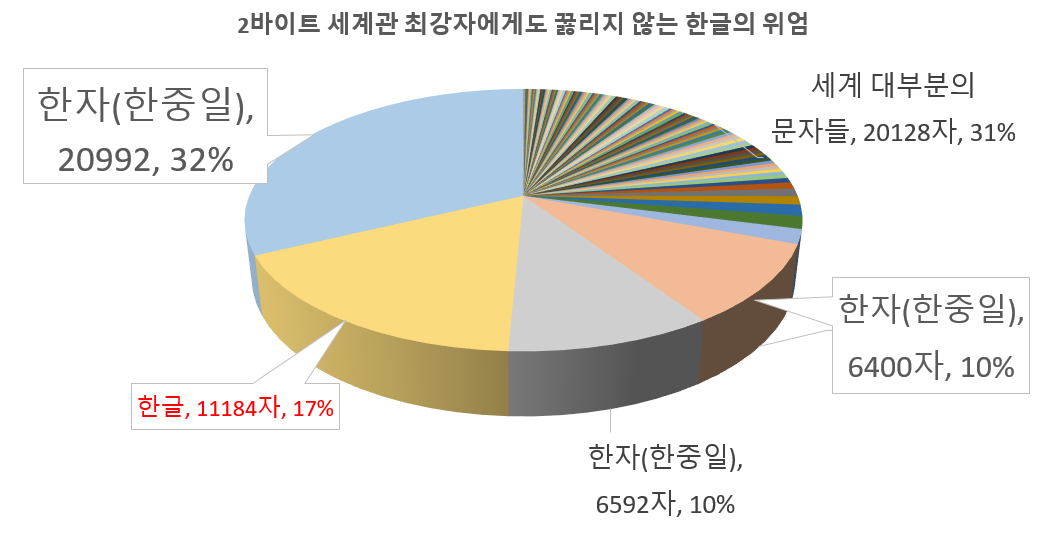
BMP에서 한가닥 하는 한글의 위엄
무려 17%나 차지하는 한국이 BMP 구역 최강자가 되지는 못했는데 불행히도 너무나도 강력한 경쟁자가 있었기 때문입니다... 그 경쟁자는 바로......

여기서 69%란 2바이트로 표현 가능한 유니코드 영역(BMP)중 차지하는 비율을 의미합니다!
표의문자인 한자를 사용하는 중국과 한자를 히라가나와 함께 혼용하는 일본입니다. 정말 재미있게도 한자문화권인 이 동아시아 삼개 국가가 BMP영역의 69%를 차지하고 있습니다. 이렇게 보니 정말 엄청난 욕심쟁이들네요. ^0^ ㅋㅋㅋㅋ
사실 한자야 뭐 워낙 문자 개수도 많고 중국인들 조차도 배우기 어렵다고 인정하는 글자인 만큼 개수가 많은건 알겠는데 한글은 왜 이렇게 개수가 많은걸까요? 한글의 자모는 합쳐서 24개 밖에 되지 않는데 말이죠~! (⊙_⊙)?
그 이유는 한글은 표음문자이지만 독특하게도 자모를 합쳐서 한글자씩 표현하기 때문입니다. 글자는 자모를 나열하여 만들지만 표현은 한자처럼 한글자씩 표현하니까요. 이는 다른 언어에서 찾아보기 힘든 한글만의 독특함이라고 할 수 있습니다. 그래도 정말 다행인것은 한자처럼 계속해서 새로운 뜻을 가진 문자가 생기는 것이 아니기에 정확히 11,172가지의 닫힌 문자집합으로 표현할 수 있다는 점입니다.
유니코드 BMP 영역에서 한글의 위치는 시작 글자인 "가"인 U+AC00 부터 "힣"(힣히히히힣) 까지인 U+D7A3 까지 범위입니다. (유니코드 한글 실라버스 에서 확인 가능합니다.)
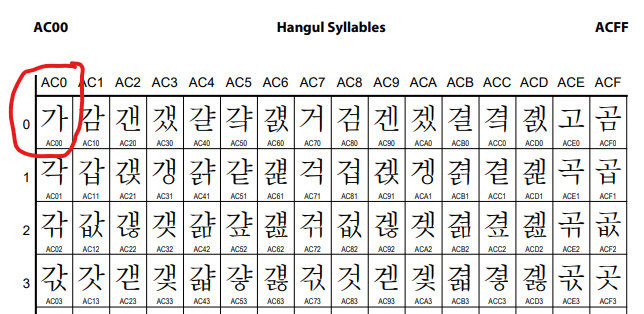
한글의 시작인 "가"는 U+AC00 이다.
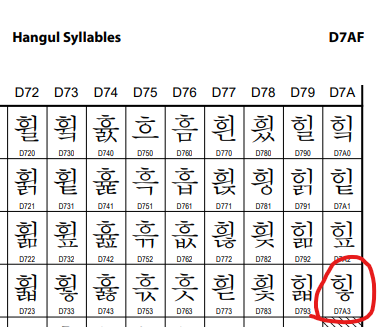
한글의 마지막은 U+D7A3 인 "힣" 이다
이렇게 세계는 유니코드를 통해 일관성을 가지고 전세계의 모든 문자를 표현할 수 있었고 점점 더 유니코드를 사용하는 쪽으로 기울게 되어 현재는 문자열 표현의 표준이 되었습니다.
유니코드의 세부적인 정보는 공식 홈페이지 home.unicode.org/ 에서 확인 하시면 됩니다.
아참, 그래서 조합형 VS 완성형 인코딩파의 전쟁은 누구의 승리로 끝났냐구요?
유니코드의 든든한 지원을 업은 완성형 인코딩파의 압도적인 승리로 막을 내리게 되었답니다. ㅎ_ㅎ (조합형 지못미...)
여담이지만 이렇듯 11,172자의 많고 아름다운 양으로 인해 한글 폰트를 만드는 작업은 굉장한 노력과 인내를 필요로 하는 작업이 되었습니다. ㅎㅅㅎ

한글폰트들이 유독 유료가 많은 이유.jpg

영문 폰트 제작 작업량(비하 의도는 없습니다. 오해 ㄴㄴ요)
유명한 문자 집합과 그 인코딩 방식을 정리한 표
| 문자 집합(Character Set) | 인코딩 방식 | 특징 |
| CP437(Code Page 437) (www.ascii-codes.com/) |
ASCII | 7비트 고정길이 인코딩 영문자만 표현 가능 |
| KS X 1001(KSC 5601-1987) | EUC-KR | 2바이트 고정길이 인코딩 한글 2,350자 밖에 지원하지 않는다(세종대왕님이 통곡하실듯) 한자는 4,888자 지원 |
| 통합형 한글 코드(Unified Hangul Code) | CP949(MS949) | 모든 한글(11,172자) 지원 모든 한글을 지원하기 위해 Microsoft 주도로 만들어진 문자 집합이면서 인코딩 방식이다 EUC-KR의 상위집합(SuperSet)으로 모든 EUC-KR 문자를 포함한다 표준은 아니지만 한때 표준처럼 사용되었음(특히, 윈도우 기반 운영체제에서) |
| 유니코드(Unicode) (www.unicode.org/charts/) (유니코드 한글 실라버스) |
UTF-8 | 1~4바이트 가변길이 인코딩 ASCII 인코딩과 호환성을 가짐 동아시아권 문자들이 3바이트로 표현 |
| UTF-16 | 2 or 4byte 고정길이 인코딩 한글이 2byte로 고정 |
|
| UTF-32 | 4byte 고정길이 인코딩 모든 문자가 동일하게 4byte임 |
유니코드 인코딩에 대하여 설명하기에 앞서...
우리들은 개발자입니다. 개념을 학습하고 이해하는 것이 가장 중요하지만 단순히 이해만으로는 충분하지 않습니다.
문자열 인코딩이 실제 프로그램과 파일에서 어떻게 이루어지고 또 개발자인 우리가 그 의미를 해석하는 방법을 익히는것 또한 중요하겠지요.
앞으로는 유니코드 인코딩이 어떤 종류가 있고 왜 이렇게 인코딩이 다양하며 각 인코딩마다 어떤 특징이 있는지에 대해 설명할 예정입니다. 또한 인코딩이 컴퓨터 어느 부분에 영향을 미치고 어떻게 식별가능하며 코드에서 어떻게 다루어야 하는지에 대해서도 짚고 넘어갈 것입니다. 하지만 이를 위해서는 실제로 컴퓨터에서 이뤄지는 비트 수준의 문자열 처리를 이해해야합니다. 이제부터는 실제 컴퓨터 단에서 처리되는 내용이 중점적으로 나올 예정입니다.
글을 이어가며 하나의 글로 끝을 내고 싶었지만 분량이 계속해서 늘어가기 때문에 이쯤에서 잠시 쉬어가는게 좋다고 생각했습니다. 때문에 이어지는 내용은 다음글에서 정리하도록 하겠습니다.
긴 글 읽어주셔서 감사합니다. 다음글에서 뵙겠습니다! (^0^)/
.
+ 나의 사설
여기서 문자집합인 Unicode를 그대로 사용해도 되지만 굳이 UTF-8이라는 방식으로 또 인코딩하는건 왜 그럴까?
문자집합인 유니코드를 인코딩하면 다음과 같은 장점이 있다.
장점
- 모든 유니코드 문자 표현 가능,바이트 경계를 순서대로, 혹은 역순으로 찾기 쉽다.
- 각 문자의 바이트 표현이 독립적이어 다른 문자에 영향을 주지 않는다. (소프트웨어와 호환성 가짐)
- 첫 바이트만 사용하여 해당 바이트 표현의 길이를 결정할 수 있다. 문자열을 매우 쉽게 얻을 수 있다.
- 인코딩에 간단한 비트연산만 사용되어 효과적이다.
- ASC||코드와 대응되는 코드들은 1byte로 인코딩돼서 오히려 이득이다
단점
- 대부분의 UTF-8 문자열들은 기존 인코딩 문자열보다 크기가 크다.